
记录一次网站被刷请求次数统计
前言
今天突然收到多吉云的通知,说请求数激增,我的个人生活博客,https://my.404.pub两个小时内cdn请求数量达到两百多万次:
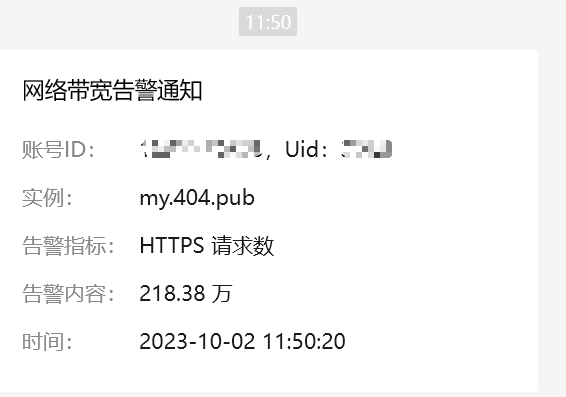
着实离谱,怕不是又惹了何方神圣。
看到后我赶紧上多吉云后台登录,做了一下补救,好在流量并没有消耗很多,只是请求数被刷了两百多万次。
于是赶紧去限制了一下请求的访问限制,防止被一直刷请求次数。

但是,单单这样限制也是会被一直消耗请求次数,不能从根本上解决问题,于是我等时间到了后,去下载了多吉云的日志文件,打算统计一下刷的ip地址然后将它们屏蔽掉。
下载日志文件后,我发现有五十多兆...人为去统计一个一个ip肯定是不现实的...

统计每个ip访问次数
人为统计不现实,于是我想到了用python,对这个文件的数据进行统计:
首先看看文件里面的数据格式,文件 内容太多,这里就列举几条数据作为展示:
20231002112543 104.239.97.108 my.404.pub / 0 -1 -1 0 NULL 7095 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36" "(null)" GET HTTPS miss 51287
20231002112543 104.239.97.138 my.404.pub / 0 -1 -1 0 NULL 7088 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36" "(null)" GET HTTPS miss 44763
20231002112543 104.238.14.206 my.404.pub / 0 -1 -1 0 NULL 7169 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36" "(null)" GET HTTPS miss 55665
20231002112543 104.239.97.78 my.404.pub / 178 -1 -1 524 NULL 9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36" "(null)" GET HTTPS hit 44341这样一大串数据摆在面前,人为的话...就算了...
然后直接开始编写代码,大概思路是通过读取文件内容,统计提取出每个ip出现的次数,然后用降序的方式写入新的result.txt文件,便于我查看哪些ip是频繁发起请求的。
实现的python代码如下:
# 打开文件
with open('data1.txt', 'r') as f:
# 初始化字典
ip_dict = {}
# 遍历文件中的每一行
for line in f:
# 通过空格分割每一行的元素
items = line.split()
# 取出第二个元素作为 IP
ip = items[1]
# 如果 IP 在字典中已经存在,则将其对应的value+1
if ip in ip_dict:
ip_dict[ip] += 1
# 如果 IP 在字典中不存在,则添加到字典中,并将其对应的value置为1
else:
ip_dict[ip] = 1
# 对字典按照 value 值进行排序,并将排序结果写入 result.txt 文件
with open('result.txt', 'w') as f:
for k, v in sorted(ip_dict.items(), key=lambda x: x[1], reverse=True):
f.write(f'ip: {k}, 出现次数: {v}\n')逻辑上还是比较简单的实现逻辑的,然后通过这样操作,最后得到了result.txt让我一览所有访问ip的次数,然后就可以愉快地屏蔽了。
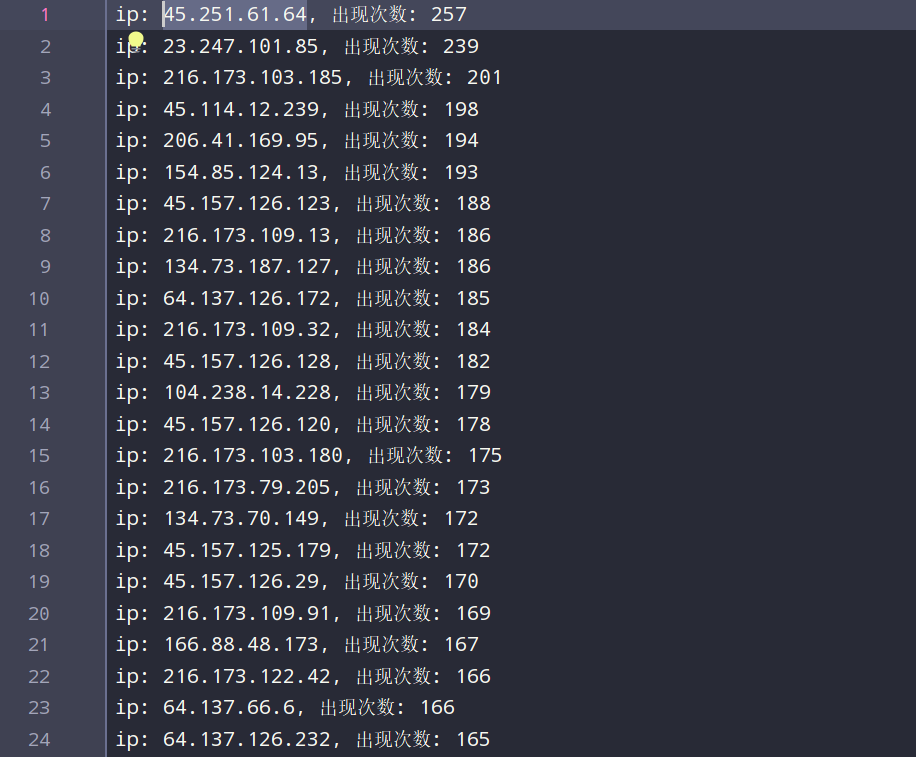
这些都是些高频访问的ip,我会去查一下它们地址,发现都是海外请求,果断直接给屏蔽了。
最后
最后,其实这次被刷,虽然量并不是很大,但是也给我们敲响了警钟,被攻击,被刷的概率还是有的,所以还是要做好万全的准备,包括但不限于做好防护的措施,比如限制最高访问频率等策略,减少自己的损失...
正文完
评论区


